如何让一个程序更快?
在CPU的设计中, 有一个经典公式叫做: Iron’s Law:
- 程序运行的时间 = 程序的指令总数 x 平均一个指令的周期数(Cycles Per Instruction, CPI) x 一个周期的时间(cycle time).
因此, 同这个公式来看, 有三种提高性能的方法:
- 减少指令总数:
- 采用更好的算法.
- 采用更好的编译器.
- 选择更好的ISA.
- 减少一个指令的平均周期数.
- CPU的微架构.
- 减少cycle time, 提高时钟频率.
- CPU的微架构.
- 选择更好的工艺.
一般来说, CPI和时钟频率是trade off的关系.
- 降低CPI, 设计复杂度就会上升, 时钟频率就会降低.
- 通过增加流水线级数提高时钟频率的话, 当分支预测失败时, 会有更大的penalty, 导致CPI猛增.
常见的例子
对于超标量处理器/VLIW处理器来说, 一个周期能够执行多个指令, 可以大大减少CPI.
采用更深的流水线, 能够减少cycle time, 提高时钟频率.
采用更好的EDA也可以提高时钟频率.
采用更好的硅工艺, 也可以提高时钟频率.
增加页表的级数: 会增加CPI, 因为TLB Miss后需要更多周期来处理.
流水线设计
流水线的基本信息
流水线设计可以降低cycle time, 提高时钟频率.
当CPU没有流水线时, 假设它的cycle time是$D$, 假设使用了$n$级流水线, 那么cycle time就会变成: $\frac{D}{n} + S$, 其中$S$是流水线寄存器的延迟.
但是, 加入流水线后, 面积会变大, 假设$G$表示没有流水线时的面积, $L$表示流水线寄存器及其附带的控制逻辑所增加的面积, 那么加入$n$级流水线后, 面积为: $G + nL$.
此时, 我们希望找到一个流水线级数$n$, 使得加入流水线后, cycle time和面积的乘积最小, 也就是函数:
最小, 这个函数存在极小值点.
CPU中的流水线的划分
划分时需要注意:
- 尽量让每个流水线阶段的时间近似相等.
- CPU的cycle time取决于耗时最长的流水线阶段.
对于CISC指令来说, 由于指令长度可变, 对于流水线的任何一个阶段, 耗时变化都会很大, 很难用流水线进行实现.
对于RISC指令来说, 指令长度固定精简, 因此更适合用流水线进行实现.
典型的RISC指令流水线划分如下:
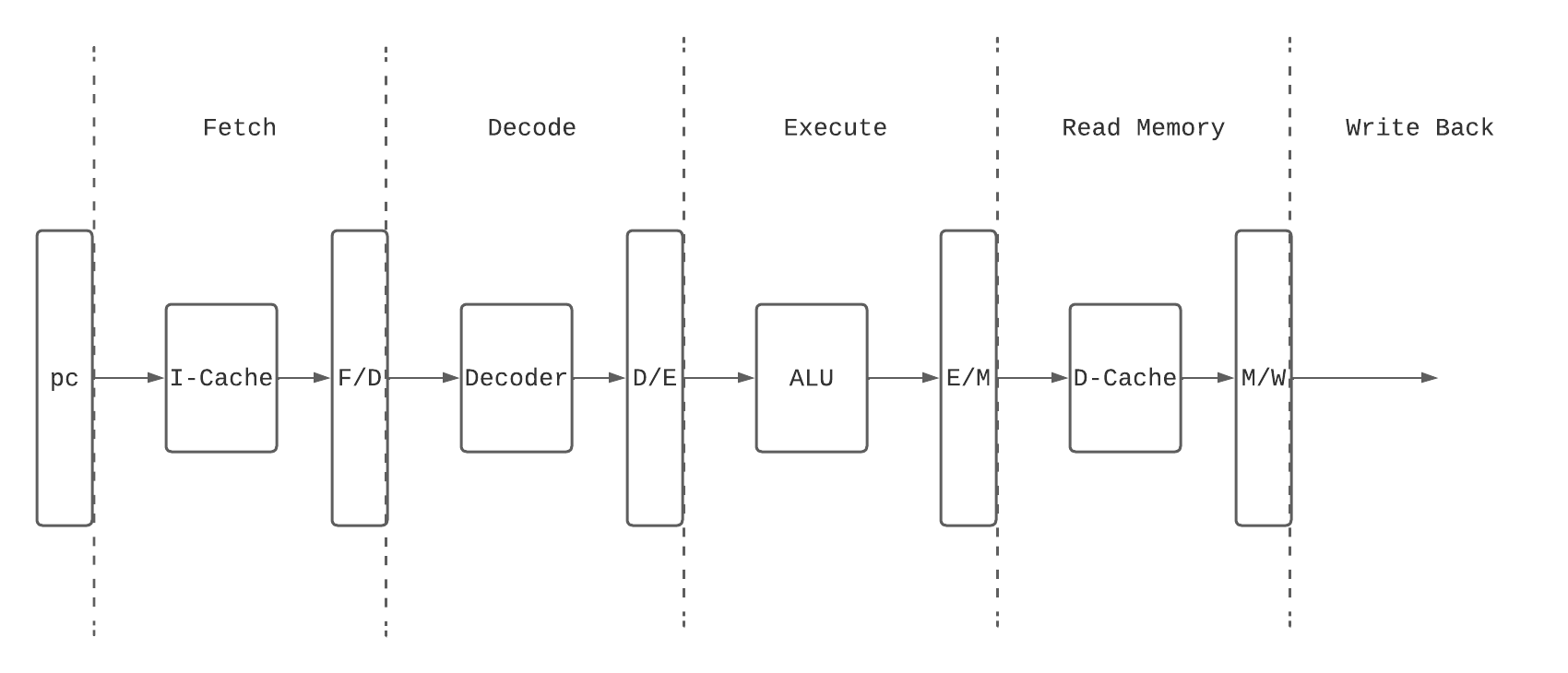
- Fetch: 从PC作为索引, 读取I-Cache中的指令, 然后放到指令寄存器中.
- Decode: 将指令进行解码, 然后读取Register File.
- Execute: 完成计算任务, 包括地址计算.
- Read Memory: 访问D-Cache/物理内存, 只针对load/store类型的指令, 其他指令在这个阶段不做任何事情.
- Write Back: 如果指令存在目的寄存器, 需要将最后结果写入目的寄存器.
实际上, 上面的流水线划分并不是最优化的, 各个阶段的延时差距可能比较大, 如果需要优化, 可以采用下面的方法:
- 合并: 将若干流水线阶段进行合并, 可以把流水线各个阶段的延时变得均衡, 适用于对性能要求不高的低功耗设计.
- 拆分: 将流水线深度变深, 可以获得更高的时钟频率, 但是面积增大, 功耗增多, 分支预测penalty增加.
指令相关性
阻碍程序并行执行的根本原因在于指令之间存在相关性, 一般有三种相关性:
- RAW: 上一个指令写一个寄存器, 下一个指令就要把它读出来.
- 这时, 必须等到上一个指令写完, 下一个指令才能读.
- 这种相关性无法避免.
- WAR: 上一个指令正在读一个寄存器, 下一个指令要写这个寄存器.
- 需要等到上一个指令读完, 下一个指令再写.
- 这种相关性可以避免, 只需要下一个指令写到别的寄存器就行.
- WAW: 上一个指令和下一个指令写了同一个寄存器.
- 需要等到上一个指令写完, 下一个指令再写.
- 这种相关性也可以避免, 只需要下一个指令写到别的寄存器就行.
三种相关性不仅适用于寄存器, load/store指令中的地址也适用.
如果是CPU顺序执行, WAR和WAW不会发生, RAW可以通过bypass的方式解决.
顺序执行
一般来说, Superscalar CPU执行指令可以分为四个阶段:
- Frontend: Fetch & Decode.
- Issue: 把指令送到FU.
- Write Back: 将FU算完的数据写到一个Buffer中.
- Commit: 将Buffer中的数据同步到寄存器中.
如果顺序执行, 那么这四个阶段都是顺序的.
如果乱序执行, 那么Issue和Write Back是乱序的, 其他的都是顺序的.
顺序超标量处理器的流水线
顺序执行的Superscalar CPU的流水线如下:
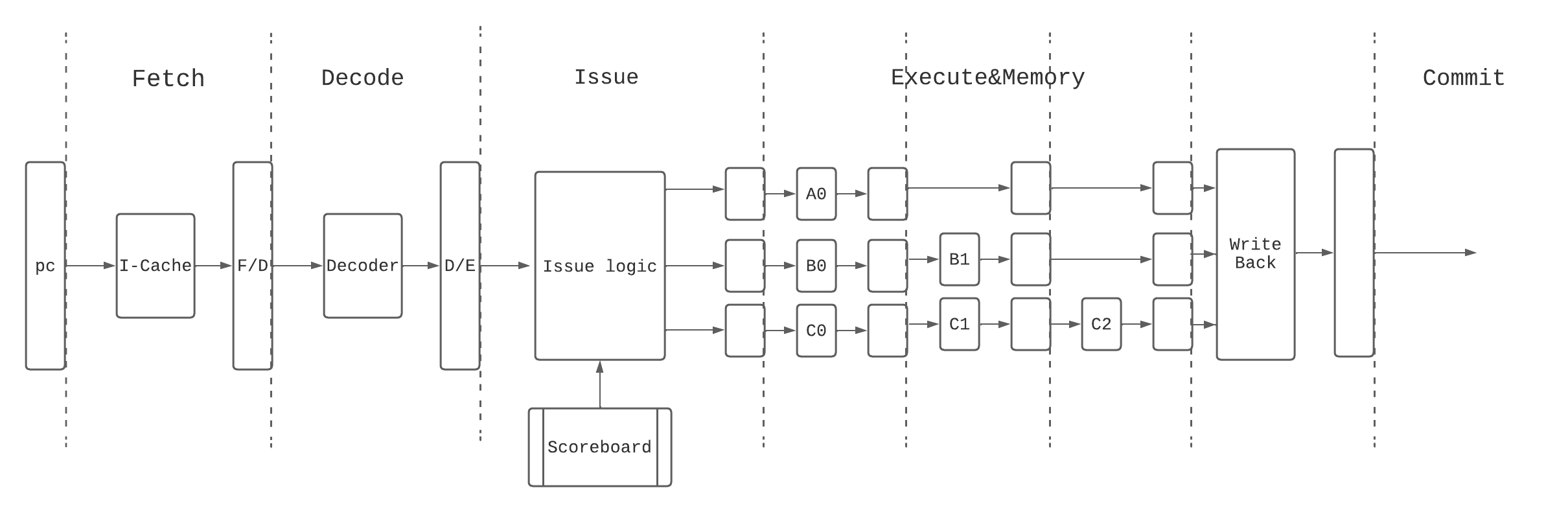
要实现这个流水线, 需要以下结构:
- 要有多个FU.
- 为了保证Write Back是顺序执行的, 所有FU计算的流水线阶段必须相等.
- ScoreBoard用来辅助Issue, 记录了流水线中每条指令的执行情况.
ScoreBoard的结构
ScoreBoard会对每个架构寄存器记录一个表项, 这个架构寄存器就是指令的目的寄存器.
在ScoreBoard中一般会记录以下信息:
- 这个指令的结果是否已经被写入架构寄存器?
- 这个指令在哪个FU中运行?
- 这个指令到达FU的哪个阶段了?
- 如果到达最后阶段, 就可以进行bypass.
一个指令只有在ScoreBoard中查询到它的源操作数已经准备好了, 并且后面没有指令阻塞才能够被issue.