Dispatch
CPU中, 当指令经过了Renaming阶段之后, 就到达了Dispatch阶段.
Dispatch是将重命名后的指令写入流水线中的很多缓存, 这是顺序执行和乱序执行的一个分界点.
具体来说缓存会有以下几种:
- Out-of-Order Issue Queue:
- CPU中大部分的指令都可以乱序执行, 这些指令的信息会先被写入OoO IQ, 之后等操作数准备好之后, 再被FU执行, 不用理会这条指令的原始顺序.
- 这种Issue Queue不是FIFO, 需要单独设计.
- In-Order Issue Queue:
- CPU中, 有一些指令需要顺序执行:
load/store指令: 当load/store指令的源操作数准备好之后, 还必须等到它之前的所有load/store指令执行完, 这条指令才能到FU去执行.
- 这种Issue Queue本质上就是FIFO.
- CPU中, 有一些指令需要顺序执行:
- ROB:
- 本质上是一个FIFO.
- 指令会按照原始的顺序写入ROB.
- ROB也会记录指令执行过程中的一些信息, 例如异常等.
- 即使有些指令很早就计算完了, 它也必须等到前面指令commit后才能commit, 也就是In-order commit.
Issue
Issue也叫发射, 是把源操作数准备好了的, 并且符合一定条件的指令, 从Issue Queue中选出来, 送到FU去执行的过程.
Issue这个过程包括三个重要的步骤:
- 分配(Allocate): 指令放到Issue Queue的哪个地方?
- 选择(Select): 当多个指令的源操作数准备好之后, 哪些指令要送到FU中?
- 唤醒(Wakeup): FU得到结果之后, 将Issue Queue中所有相关的指令的源操作数置为有效.
Issue Queue的设计
集中式/分布式
在超标量CPU中, 一般都会有很多的FU, 如果这些FU共用一个Issue Queue, 那么这个Issue Queue就是集中式的.
集中式Issue Queue的优缺点?
- 优点: 对Issue Queue的利用效率很大, 不会浪费空间.
- 缺点:
- 容量很大, Select/Wakeup电路的面积和延迟会很大.
分布式Issue Queue就是为每一个FU都配备一个Issue Queue, 每一个Issue Queue的容量不会很大.
分布式Issue Queue的优缺点?
- 优点: 可以简化Select电路的设计.
缺点:
- 如果一个FU的Issue Queue满了, 即使其他FU的Issue Queue还有空间, 对应的指令也无法进行写入Issue Queue, 也就是说有空间闲置了.
- 由于Issue Queue比较分散, Wakeup的布线成本也会上升.
一般的CPU都会选择将若干个FU共用一个Issue Queue, 算是一种折中方案.
Data-Capture/Non-Data-Capture
这个区别主要在于: 指令是在被写入Issue Queue之前读取物理寄存器, 还是在被写入Issue Queue之后读取物理寄存器.
- 发射之前读取叫Data-capture.
- 发射之后读取叫Non-Data-Capture.
Data-Capture
Data-Capture的工作原理如下:
- 指令被写入Issue Queue之前, 读取这个指令源操作数中物理寄存器的值, 写入Issue Queue.
- 如果这个源寄存器是not available的, 那么就会先把物理寄存器的编号写入Issue Queue.
- 当指令被Select时, 就可以直接从Issue Queue中读取数值, 然后送到FU去计算.
- 当指令被Select时, 这个指令的目的寄存器编号会在Issue Queue中进行广播.
- 如果其他指令发现这个编号和自己源操作数的编号相同, 那么就会在对应的源操作数上进行标记.
- 当FU计算完成后, 就会把数据写到刚刚标记的源操作数上, 这个过程就像Issue Queue捕捉FU中计算的数据.
在CPU中, 有两个名词:
- Issue Width: 每个周期最多可以发射的指令个数.
- Machine Width: 每周期最多可以decode和rename的指令个数.
一般来说, 需要让Issue Width大于Machine Width, 才能够保证流水线平衡, 因此, 现代高性能处理器一般会配备多个FU, 来提高Issue Width.
如果采用Data-capture, 那么物理寄存器的读端口的个数应该是Machine Width x 2, 这个值一般比较小.
但是如果采用Data-capture, Issue Queue需要存数据, 会导致Issue Queue占用的面积比较大.
这种架构下, 功耗较高, 因为一个指令的源操作数会经历两次读, 一次写:
- 读: 从物理寄存器中读出来.
- 写: 写入Issue Queue.
- 读: 指令被Select之后, 再从Issue Queue中读出来.
Non-Data-Capture
Non-Data-Capture的工作原理如下:
- 指令被写入Issue Queue时, 将这个指令的物理寄存器编号写进Issue Queue.
- 指令被Select之后, 根据这个指令物理寄存器的编号, 读取物理寄存器, 送到FU执行.
设计的优缺点?
优点:
- Issue Queue不用存数据, 占用的面积小了.
- 每个源操作数只会被读一次(就是从物理寄存器中读出来), 功耗较低.
缺点: 物理寄存器的端口个数变成了
Issue Width x 2, 这个值一般比较大.
压缩/非压缩
压缩
压缩指的是, 当Issue Queue中的一条指令被Select, 离开Issue Queue之后, 这个空隙会不会被后面的指令填上, 这个过程就好比从一摞书中抽走一本后, 这个空隙会被上面的书填满一样.
要实现这种压缩的效果, 需要给Issue Queue中的每个表项加一个多路选择器:
- 当这个表项是空白时, 选择上面表项的内容.
- 当这个表项不是空白时, 选择自己的内容.
这样就能实现每周期压缩一个表项的发射队列, 如果要实现每周期能够压缩两个表项的发射队列, 那么多路选择器就要有三个来源(自己的, 上面一个的, 上面两个的).
设计的优缺点?
- 优点:
- Select电路比较简单, 一般Select电路都会从所有ready的指令中, 选择最老的那一条送到FU, 这就是oldest-first方法, 这种压缩方式的Issue Queue已经按照指令的新老关系排好序了.
- 分配电路简单, 只需要放到Issue Queue的最上面即可.
- 缺点:
- 功耗较大.
- 加入两个FU共用一个Issue Queue, 那么每周期就会有两个指令离开Issue Queue, 此时就需要每周期压缩两个指令, 会导致布线资源较大, 面积较大.
非压缩
非压缩指的是, 当Issue Queue中指令被Select离开Issue Queue后, 这个空隙不会被后面的指令填上.
那么此时, 空闲空间在Issue Queue中的分布将没有规律.
设计的优缺点?
- 优点: 面积和功耗较低.
- 缺点:
- 分配电路比较复杂, 如果一个周期需要向Issue Queue写入多条指令, 那么需要从Issue Queue中找到多个空闲空间, 电路很复杂.
- Select电路如果要实现oldest-first, 那么算法会比较复杂.
Issue的流水线设计
一条指令要被送到FU中, 需要三个条件满足:
- 这条指令的源操作数被标记为ready.
- 这条指令被Select.
- 这条指令能够从Physical Register, Issue Queue或者Bypass处获得源操作数的值.
在实际过程中, Issue阶段被划分成了Select和Wakeup阶段.
- Select阶段: 等待我这条指令被Select.
- Wakeup阶段: 当我这条指令被Select之后, 我会把目的寄存器进行广播, 然后唤醒Issue Queue中对应的源寄存器.
- RegRead阶段: 从bypass, Physical Register或者Issue Queue处获取源寄存器的值.
此时, 这里有一个Tradeoff, Select阶段和Wakeup阶段是在一个周期内完成, 还是放在两个周期完成.
如果Select阶段和Wakeup阶段在一个周期内完成, 那么:
- 优点:
- IPC会有较大提升, 此时有RAW依赖的两条指令可以获得最大的并行度.
- 流水线级数少, 功耗降低.
- 缺点:
- 频率降低.
如果Select和Wakeup放在两个周期内完成, 那么:
- 优点:
- 频率提高.
- 缺点:
- 分支预测失败的penalty提高.
- Cache访问的周期数增加(Cache访问时间是固定的, 频率提高, 那么周期数也会增多).
- 功耗增大.
Select算法的设计
oldest-first算法
Oldest-first算法的合理性:
- 流水线中越老的指令, 与它存在相关性的指令越多, 选择它可以唤醒更多指令.
如何实现Oldest-first算法?
- 由于指令是按照程序的顺序写入ROB的, 因此, 可以根据ROB中的信息来获取指令的新老信息.
但是ROB本质上是一个循环FIFO, 仅仅靠指令在ROB中的地址无法获取指令的新老信息, 这时需要一个特殊的算法.
ROB中有一个写指针, 有一个读指针:
- 写指针负责将Dispatch的所有指令写入ROB, 然后移动.
- 当指令被Commit之后, 读指针会移动.
读指针和写指针会进行翻转.
此时, 可以在ROB表项的最前面加上一位s, 当写指针写入时, 会把s写入, 如果写指针出现了反转, s也会进行翻转(0变1, 1变0).
此时指令的新老关系可以这样判断:
s相同, ROB地址越小, 对应指令越老.s不同, ROB地址越大, 对应指令越老.
因此, 在Dispatch阶段, 可以将指令在ROB中的地址和s一起写进Issue Queue, 这样Issue Queue中就有了年龄信息.就可以实现oldest-first算法.
注意, 在进行选择时, 还需要将没有被Wakeup(没有ready)的指令进行排除.
实际的电路可以这样实现:
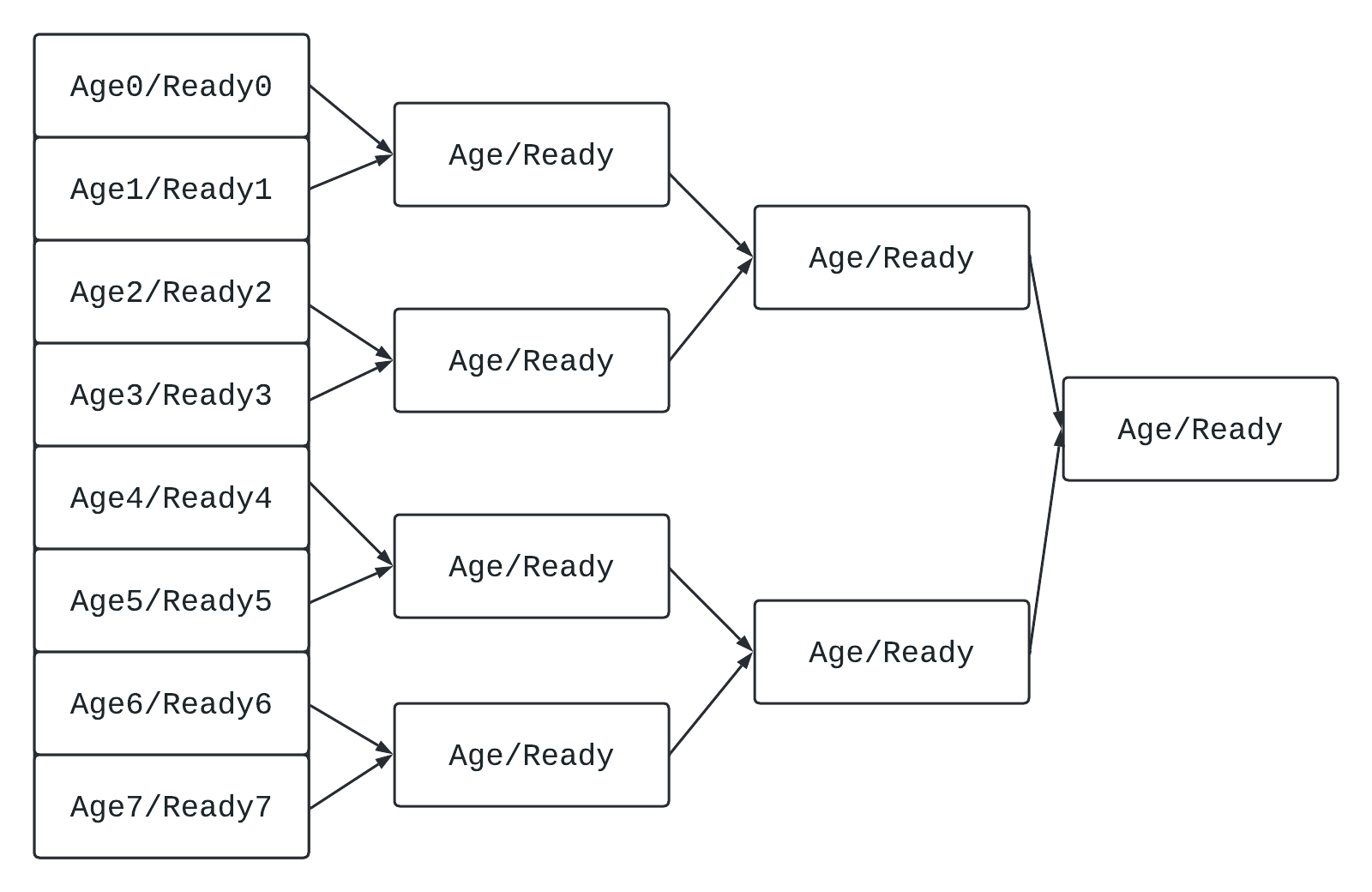
- 假设一个Issue Queue中有$n$个元素, 那么比较电路的级数就是$log_2(n)$.
- 对于两个元素之间的比较, 规则如下:
- 如果两个元素ready都是1, 选择年龄较小的.
- 如果只有一个元素ready是1, 就选这个.
- 如果两个元素ready都是0, 选哪个无所谓.
oldest-m-first算法
当$m$个FU共用一个容量是$n$的Issue Queue时, 就需要从Issue Queue中, 为每一个FU选出一个oldest的指令.
在实际实现时:
在写入Issue Queue时, 需要在Issue Queue中记录, 这个指令要给哪个FU.
需要为这$m$个FU一人准备一个oldest-first电路, 并且在oldest-first电路中比较时需要考虑FU的类型, 选出最老的, 并且是对应类型的, 并且还得是ready的一条指令.
为了提高指令的并行度, 可以增加FU的数量, 例如, 如果原本只有一个ALU, 现在可以变成两个ALU:
- 原来只有一个ALU的时候, 如果Issue Queue中同时有两个ALU指令ready了, 那么只能有一个ALU指令被Select.
- 但是如果有两个ALU, 这两个ALU指令就能同时被Select.
但是如果变成了两个ALU, 这又引入了一个新的问题:
- 一个ALU指令在被写入Issue Queue时, 它应该要到哪个ALU里.
此时可以准备一个bit, 初始化为0, 第一次要到ALU0, 然后翻转, 下次写入Issue Queue的ALU指令要到ALU1, 然后再下一次的指令进入ALU0, 然后ALU1….
但是, 如果采用这种策略, 无法保证oldest-first是正确的, 例如:
- 在一个Issue Queue中, 要到ALU0的指令对应的年龄有:
3, 2, 1, 0, 要到ALU1的指令对应的年龄有1, 1, 0, 0. - ALU0会选择年龄是3的, ALU1会选择年龄是1的, 但是按照oldest-first原则, 年龄是1的不应该被选, 因为ALU0那里还有年龄是2的更老.
因此, 为了保证oldest-first, 需要更复杂的FU分配算法.
Tradeoff
Select电路的延时和Issue Queue的容量成正比.
- 越多个FU共用一个Issue Queue, Issue Queue容量多, Select延时大.
- 越少个FU共用一个Issue Queue, Issue Queue个数多, Wakeup延时大.
因此, Select和Wakeup也是一个tradeoff的关系.
Wakeup算法的设计
单周期指令的Wakeup
首先, 单周期指令指的是这个指令能在一个周期内被FU计算出结果.
首先, 每一个FU都有一个Select电路, 当这个FU的对应的某个指令从Issue Queue中被Select后, 对于单周期指令来说, 他要在同一个周期内进行Wakeup操作.
对于每一个Select电路, 都会准备一条总线, 当这条指令被Select之后, 对应的目标寄存器会在总线上被广播到所有的Issue Queue.
对于单周期指令, Select和Wakeup为什么可以在一个周期?
对于单周期指令, 假设在周期
c, 他唤醒了一条指令, 那么在周期c+1就可以得到结果, 这个结果可以立马被bypass到下一个进入FU的指令.对于具有RAW依赖的指令来说, 只要Select/Wakeup在一个周期, 并且FU具有bypass, 那么就可以实现背靠背的运行.
多周期指令的Wakeup
对于多周期指令, FU需要若干个周期才能够将结果计算出来. 此时, Select和Wakeup就不能在同一个周期, 对于这种指令有两种处理办法 (假设这个指令需要的周期数是$n$):
- 延迟广播(Delayed Tag Broadcast): 当指令被Select后, 经过$n-1$个周期再把目的寄存器广播到总线上.
- 这种方法会让指令占用总线资源, 会导致后续指令无法利用总线.
- 延迟唤醒(Delayed Wakeup): 当指令被Select之后, 立马将目的寄存器进行广播, 但是将Isssue Queue中的源寄存器置为ready这个过程需要延后$n - 1$个周期.
- 延后若干个周期可以采用移位寄存器进行实现.
- 一般采用这种方法.
推测Wakeup
在CPU中, 有些指令在FU中执行的周期数是没办法提前知道的, 比如load/store指令, 有很多特殊情况.
此时有两种方法进行处理:
最简单的方法: Select之后, 送到FU, 等FU执行完成后再通过bypass进行唤醒(广播目的寄存器, 将Issue Queue中的源寄存器置为ready).
- 这个是早期Tomasulo算法的内容.
采用推测Wakeup, 也就是推测这个指令会在若干个周期(假设是$m$)内完成, 然后在Select后, 过了$m-1$个周期再进行延迟唤醒, 如果预测失败需要采用恢复机制.
例如以load指令为例, 由于D-Cache的命中率较高, 可以假设load指令永远命中, 此时就可以知道load指令需要执行多少个周期了.
如果猜错了, D-Cache没命中 (这个信息可以在Cache访问的流水线上得到), 那么在若干周期之后, 无法从FU的bypass处获得数据, 此时, 就需要进行恢复, 这种恢复机制有一个名字叫做Replay.
注意, 如果实现了虚拟地址, 并且Cache的结构是VIPT或者PIPT, 那么还需要假设TLB命中, 如果TLB Miss的话, 根据处理TLB Miss的方式不同, 对于推测Wakeup的恢复方式也不同:
- 如果采用软件处理TLB Miss, 那么load指令就相当于出现了异常, 会等到load指令变成流水线中最旧的指令后, 将load指令及其之后的指令全部抹掉, 然后运行exception handler, 然后重新将load指令及其后面的指令放到流水线上.
- 如果采用硬件处理TLB Miss, 需要进行Replay.
注意: 对于多级Cache来说, 可以采用多级的推测Wakeup:
- 先假设L1 Cache命中, 有一个推测值.
- 猜错了, 再假设L2 Cache命中, 再有一个推测值.
- …
Replay的实现方式有很多种, 取决于这个指令在被Select之后, 会不会立马离开Issue Queue.
Issue Queue Based Replay
如果这个指令被Select, 送到FU里的时候, 它不会离开Issue Queue, 那么就需要Issue Queue Based Replay.
此时, 每一条指令在Issue Queue中会多一个属性, 叫做issued:
是1: 表示这个指令被送到FU执行了, 但是还没有离开Issue Queue.
当一个指令被Select时,
issued位会被置为1.- 当
issued位被置为1时, 他就不会被Select电路选中.
如果这个指令被发现推测Wakeup错误, 那么所有被它唤醒的, 并且issued是1的指令都需要重新被Wakeup/Select.
- 具体replay的做法就是把这条指令的
issued位置为0. - 然后将推测Wakeup失败的指令唤醒的所有源寄存器设置为not-ready.
那什么时候这些指令才能够离开Issue Queue?
只有当这些指令能够确认“正确执行”之后, 才可以离开Issue Queue.
“正确执行”的等价条件是: 所有唤醒这条指令的原指令都确定不会出现推测Wakeup的失败.
对于某些指令, 可以在FU计算流水线的某个阶段获取这条指令是否Wakeup成功, 这样被它唤醒的指令就可以提前离开Issue Queue.
那么, 还有一个重要的问题, 假设一个指令被发现推测Wakeup失败, 那么, 我如何才能找到所有被它唤醒的, 并且
issued是1的指令?
如果采用预测Wakeup, 有两个重要的time slots:
- Independent Window: 从这条指令被Select/Wakeup, 到Issue Queue中源寄存器置为ready, 中间差了$m-1$个周期, 这个$m$是预测Wakeup的推测值.
- Speculative Window: 从Issue Queue中源寄存器置为ready, 到发现这条指令推测Wakeup失败.
如果发现一个指令推测Wakeup失败:
- Non-Selective Replay:
- Independent Window中被Select的指令, 一定和Wakeup失败的指令没有关系, 因此不用replay.
- 因此, 只需要将Speculative Window中被Select指令replay即可.
- 注意: 在Speculative Window中被唤醒的指令, 不一定和之前Select的指令具有相关性, 此时如果把Speculative Window中的指令全部抹掉, 那么会让一些没有相关性的指令也被抹掉, 造成性能浪费.
如果采用这种方式, 还会有一个问题, 对于推测Wakeup失败的指令, 它唤醒的所有源寄存器需要设置为non-ready, 同时, 对于这些non-ready的源寄存器所在的指令, 它也可能在Speculative Window中唤醒其他指令, 此时, 我还需要把这些其他指令对应的源寄存器也设置为non-ready(形成了一个依赖的链条). 因此, 需要提供一种机制, 来检测如果一个指令出现了Wakeup失败, 我需要将哪些源寄存器设置为non-ready, 这种机制叫做Vector算法.
Vector算法的机制?
首先, 对于每一类不能确定FU多少个周期能完成的指令, 都需要一套独立的Vector算法, 这里以load为例.
对于每一个物理寄存器, 都有一个$n$位的Load-Vector, 其中这个$n$表示能够在流水线上同时存在的load指令的个数.
对于每一条指令:
- 如果指令不是load, 并且存在目的寄存器, 那么目的寄存器的Vector值等于源寄存器Vector的按位或.
- 对于load指令, 它的目的寄存器的Vector值是源寄存器的Vector值, 在从右往左数的最后一个0把它变成1即可.
寄存器的Vector的赋值过程发生在寄存器重命名.
当一个load指令被发现推测Wakeup失败之后:
- 看一下这个load指令的Vector值, 找到它从右向左数第一个1所在的下标
idx. - 然后遍历所有物理寄存器的Vector, 如果它的Vector值的第
idx位是1, 那么这个寄存器就需要在replay过程中被置为non-ready.
但是, 对于这种Vector算法, 他限制了流水线中同时存在的load指令只能有$n$条.
- 当流水线较浅时, 同时存在于流水线中的load指令不会很多, 因此Vector算法可以接受.
- 当流水线较深时, 这种方法不可以.
因此, 可以考虑另一种算法, 叫做Position Vector算法.
Position Vector算法的工作机制?
对于每一类不能确定FU多少个周期能完成的指令, 都需要一套独立的Position-Vector算法, 这里以load为例.
对于每一个物理寄存器, 都有一个$n$位的Position-Vector, 其中这个$n$等于load指令在流水线上执行的阶段数+1.
对于每一条指令:
- 如果指令不是load, 并且存在目的寄存器, 那么目的寄存器的Position-Vector值等于源寄存器Position-Vector按位或.
- 对于load指令, 它的目的寄存器的Position-Vector值是源寄存器Position-Vector值, 然后将最左边的第一个0变成1即可(表示新的load指令在Select阶段).
每过一个周期, Position-Vector的值都会逻辑右移1位, 用来追踪所有load指令在流水线中的位置.
当一个load指令被发现推测Wakeup失败之后:
- 看一下这个load指令的Position-Vector值, 找到它从右向左数第一个1所在的下标
idx. - 然后遍历所有物理寄存器的Position-Vector, 如果它的Position-Vector的第
idx位时1, 那么这个寄存器就要在replay过程中被设置为non-ready.
- 当一条指令被Select, 它的目的寄存器的Position-Vector也会进入后续的流水线.
- 当某条指令被发现推测Wakeup失败后, 遍历所有指令的目的寄存器的Position-Vector, 如果Position-Vector的第
idx位是1, 那么这条指令就需要被replay, 也就是在Issue Queue中的issued位被设置成0. - 这种做法叫Selective-Replay.
Issue Queue Based Replay设计的优缺点?
- 优点: 容易实现, 复杂度较低.
- 缺点: 对于Issue Queue的利用率降低: 如果推测Wakeup正确, 那么在Select和Wakeup间隔的这些周期, 被一开始Select的指令唤醒的这些指令理论上不应该占用Issue Queue, 由于Issue Queue的容量可以直接影响CPU的并行度, 因此会导致CPU性能下降.
- 如果一个指令被Select, 并且它的目的寄存器的Position-Vector全0, 那么说明它不依赖任何load指令, 此时就可以马上离开Issue Queue.
Replay Queue Based Replay
当一条指令被Select之后, 他会立即离开流水线, 进入Replay Queue.
当一条指令确认能够“正确执行”时(被commit), 就会离开Replay Queue.
当一条指令被发现推测Wakeup失败后:
- 与它相关的指令需要在流水线中抹掉.
- 与它相关的指令需要在Replay Queue中重新被Select, 在Replay Queue中的Select过程比在Issue Queue中Select有更高的优先级.
如何选择Issue Queue Based Replay还是Replay Queue Based Replay?
- 如果Issue Queue是Data-Capture的, 那么指令被Select到指令被发现推测Wakeup失败, 需要replay的间隔周期数不会太多, 需要被replay的指令也不会太多, 因此可以Issue Queue Based Replay.
- 如果Issue Queue是Non-Data-Capture的, 那么指令被Select到指令被发现推测Wakeup失败, 需要replay的间隔周期数会很长 , 因为还有一个读取物理寄存器的阶段, 因此需要被replay的指令可能很多, 可以采用replay queue减少Issue queue的压力.